> ## Documentation Index
> Fetch the complete documentation index at: https://private-7c7dfe99-fix-nav-issues.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# 托管
> 部署托管 ClickStack
export const TrackedLink = ({href, eventName, children, ...rest}) => {
const handleClick = () => {
try {
if (typeof window !== "undefined" && window.galaxy && eventName) {
window.galaxy.track(eventName, {
interaction: "click"
});
}
} catch (e) {}
};
return
{children}
;
};
export const Image = ({img, alt, size}) => {
return
 ;
};
本**指南适用于现有的 ClickHouse Cloud 用户**。如果你刚开始使用 ClickHouse Cloud,我们建议先阅读面向托管 ClickStack 的 [入门](/zh/clickstack/getting-started/managed) 指南。
在这种部署模式下,ClickHouse 和 ClickStack UI (HyperDX) 都托管在 ClickHouse Cloud 中,从而将用户需要自行托管的组件数量降至最低。
除了减少基础设施管理,这种部署模式还能确保身份验证与 ClickHouse Cloud SSO/SAML 集成。与自托管部署不同,你也无需部署 MongoDB 实例来存储应用状态,例如仪表盘、保存的搜索、用户设置和告警。用户还可受益于:
* 计算资源与存储分离的自动扩缩容
* 基于对象存储的低成本、近乎无限的数据保留
* 能够使用仓库独立隔离读写工作负载
* 集成式身份验证
* 自动化备份
* 安全与合规功能
* 无缝升级
在这种模式下,数据摄取完全由用户负责。你可以通过自行托管的 OpenTelemetry collector、客户端库直接摄取、ClickHouse 原生表引擎 (如 Kafka 或 S3) 、ETL 管道,或 ClickPipes (ClickHouse Cloud 的托管摄取服务) 将数据摄取到托管 ClickStack 中。这种方式是运行 ClickStack 最简单、性能也最好的方式。
;
};
本**指南适用于现有的 ClickHouse Cloud 用户**。如果你刚开始使用 ClickHouse Cloud,我们建议先阅读面向托管 ClickStack 的 [入门](/zh/clickstack/getting-started/managed) 指南。
在这种部署模式下,ClickHouse 和 ClickStack UI (HyperDX) 都托管在 ClickHouse Cloud 中,从而将用户需要自行托管的组件数量降至最低。
除了减少基础设施管理,这种部署模式还能确保身份验证与 ClickHouse Cloud SSO/SAML 集成。与自托管部署不同,你也无需部署 MongoDB 实例来存储应用状态,例如仪表盘、保存的搜索、用户设置和告警。用户还可受益于:
* 计算资源与存储分离的自动扩缩容
* 基于对象存储的低成本、近乎无限的数据保留
* 能够使用仓库独立隔离读写工作负载
* 集成式身份验证
* 自动化备份
* 安全与合规功能
* 无缝升级
在这种模式下,数据摄取完全由用户负责。你可以通过自行托管的 OpenTelemetry collector、客户端库直接摄取、ClickHouse 原生表引擎 (如 Kafka 或 S3) 、ETL 管道,或 ClickPipes (ClickHouse Cloud 的托管摄取服务) 将数据摄取到托管 ClickStack 中。这种方式是运行 ClickStack 最简单、性能也最好的方式。
### 适用场景
此部署模式尤其适用于以下场景:
1. 您已在 ClickHouse Cloud 中存有可观测性数据,并希望使用 ClickStack 进行可视化。
2. 您运营的是大规模可观测性部署,需要借助运行在 ClickHouse Cloud 上的 ClickStack 所提供的专用性能和可扩展性。
3. 您已在使用 ClickHouse Cloud 进行分析,并希望借助 ClickStack 插桩库为应用接入可观测性数据采集——将数据发送到同一个集群。在这种情况下,我们建议使用[仓库](/zh/products/cloud/features/infrastructure/warehouses)来隔离可观测性工作负载的计算资源。
## 设置步骤
以下指南默认您已创建 ClickHouse Cloud 服务。如果您尚未创建服务,请参阅托管 ClickStack 的 [入门](/zh/clickstack/getting-started/managed) 指南。完成后,您的服务将处于与本指南相同的状态,也就是说,已启用 ClickStack,并可接收可观测性数据。
### 创建新服务
在 ClickHouse Cloud 首页中,选择 `New service` 以创建新服务。
### 指定您的提供商、区域和资源
**Scale 与 Enterprise**
对于大多数 ClickStack 工作负载,我们推荐使用 [Scale 层级](/zh/products/cloud/features/cloud-tiers)。如果您需要 SAML、CMEK 或 HIPAA 合规等高级安全功能,请选择 Enterprise 层级。该层级还可为超大规模 ClickStack 部署提供自定义硬件 profile。在这些情况下,我们建议联系支持团队。
选择 Cloud 提供商和区域。
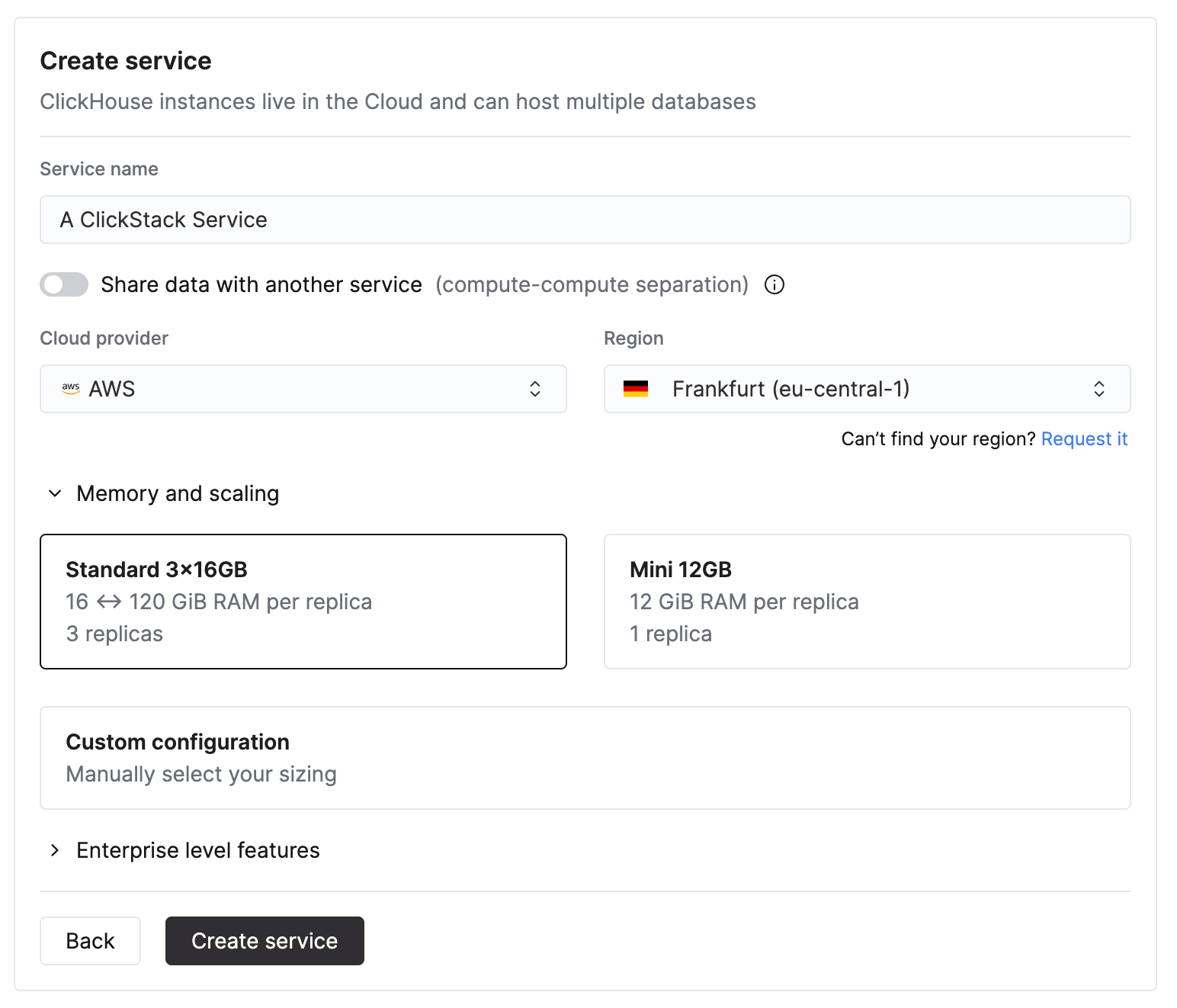 指定 CPU 和内存时,请根据预期的 ClickStack 摄取吞吐量进行估算。下表提供了这些资源的选型参考。
| 每月摄取量 | 推荐 compute |
| ------------- | --------------- |
| 每月 \< 10 TB | 2 vCPU × 3 个副本 |
| 每月 10–50 TB | 4 vCPU × 3 个副本 |
| 每月 50–100 TB | 8 vCPU × 3 个副本 |
| 每月 100–500 TB | 30 vCPU × 3 个副本 |
| 每月 1 PB+ | 59 vCPU × 3 个副本 |
这些建议基于以下假设:
* 数据量是指每月**未压缩摄取量**,适用于日志和链路追踪。
* 查询模式符合典型的可观测性用例,大多数查询都针对**最近的数据**,通常是最近 24 小时内的数据。
* 摄取在整个月内相对**均匀**。如果您预计会出现突发流量或峰值,应额外预留余量。
* 存储由 ClickHouse Cloud 对象存储单独处理,因此不会成为保留时长的限制因素。我们假设保留时间较长的数据不会被频繁访问。
如果访问模式经常查询更长时间范围、执行大量聚合,或需要支持大量并发用户,则可能需要更多 compute 资源。
虽然两个副本即可满足特定摄取吞吐量下的 CPU 和内存需求,但我们建议在条件允许时使用三个副本,以获得相同的总容量并提升服务冗余能力。
这些数值**仅为估算**,应作为初始基线参考。实际需求取决于查询复杂度、并发程度、保留策略以及摄取吞吐量的波动情况。请始终监控资源使用情况,并按需扩缩容。
指定完需求后,您的托管 ClickStack 服务将需要几分钟完成预配。在等待预配期间,您可以先浏览 [ClickHouse Cloud 控制台](/zh/products/cloud/getting-started/intro) 的其他部分。
一旦**预配完成,左侧菜单中的“ClickStack”选项将会启用**。
### 配置摄取
服务预配完成后,确保已选中该服务,然后在左侧菜单中点击 "ClickStack"。
指定 CPU 和内存时,请根据预期的 ClickStack 摄取吞吐量进行估算。下表提供了这些资源的选型参考。
| 每月摄取量 | 推荐 compute |
| ------------- | --------------- |
| 每月 \< 10 TB | 2 vCPU × 3 个副本 |
| 每月 10–50 TB | 4 vCPU × 3 个副本 |
| 每月 50–100 TB | 8 vCPU × 3 个副本 |
| 每月 100–500 TB | 30 vCPU × 3 个副本 |
| 每月 1 PB+ | 59 vCPU × 3 个副本 |
这些建议基于以下假设:
* 数据量是指每月**未压缩摄取量**,适用于日志和链路追踪。
* 查询模式符合典型的可观测性用例,大多数查询都针对**最近的数据**,通常是最近 24 小时内的数据。
* 摄取在整个月内相对**均匀**。如果您预计会出现突发流量或峰值,应额外预留余量。
* 存储由 ClickHouse Cloud 对象存储单独处理,因此不会成为保留时长的限制因素。我们假设保留时间较长的数据不会被频繁访问。
如果访问模式经常查询更长时间范围、执行大量聚合,或需要支持大量并发用户,则可能需要更多 compute 资源。
虽然两个副本即可满足特定摄取吞吐量下的 CPU 和内存需求,但我们建议在条件允许时使用三个副本,以获得相同的总容量并提升服务冗余能力。
这些数值**仅为估算**,应作为初始基线参考。实际需求取决于查询复杂度、并发程度、保留策略以及摄取吞吐量的波动情况。请始终监控资源使用情况,并按需扩缩容。
指定完需求后,您的托管 ClickStack 服务将需要几分钟完成预配。在等待预配期间,您可以先浏览 [ClickHouse Cloud 控制台](/zh/products/cloud/getting-started/intro) 的其他部分。
一旦**预配完成,左侧菜单中的“ClickStack”选项将会启用**。
### 配置摄取
服务预配完成后,确保已选中该服务,然后在左侧菜单中点击 "ClickStack"。
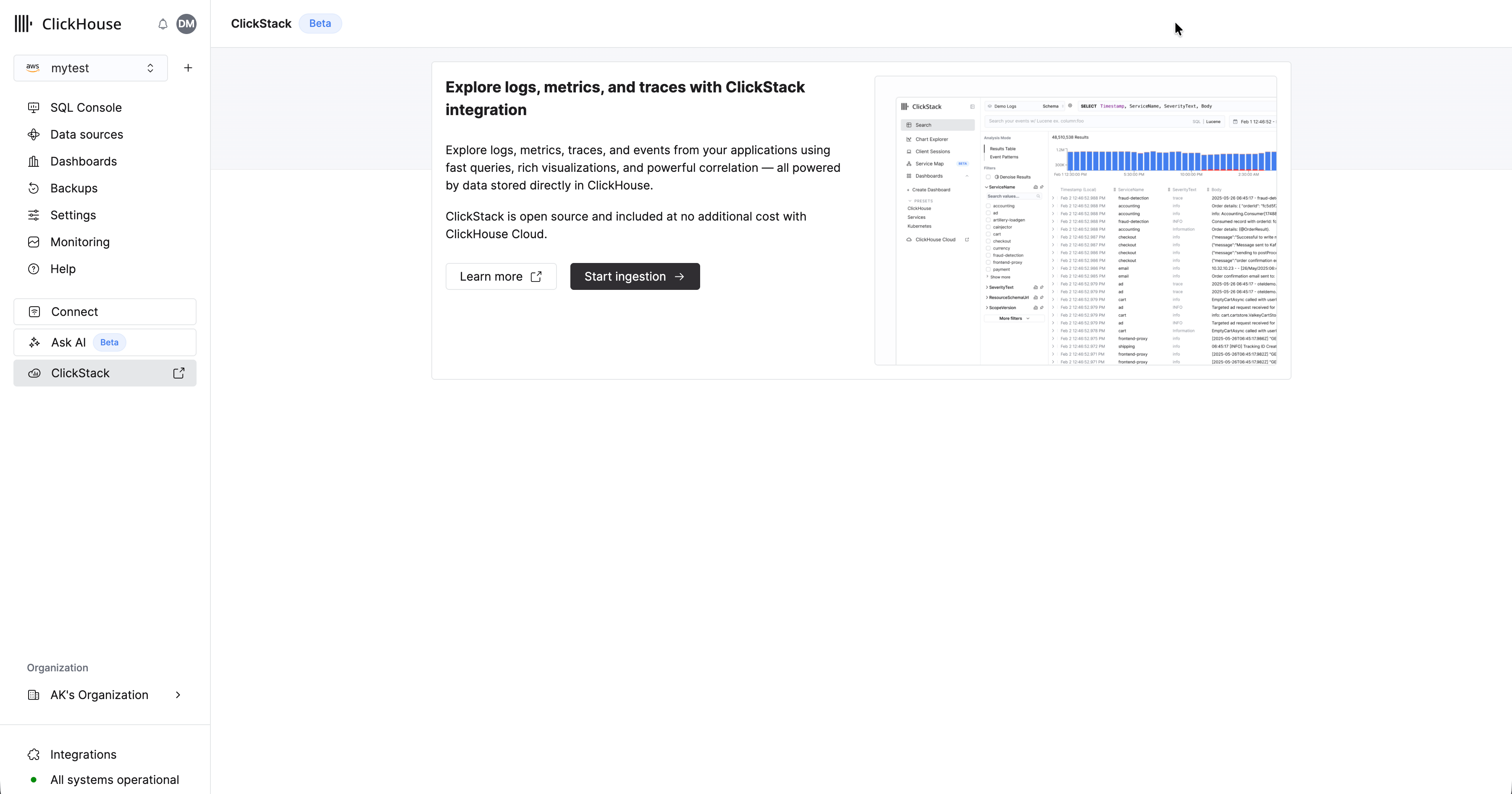 选择“开始摄取”后,系统会提示你选择摄取源。托管 ClickStack 主要支持 OpenTelemetry 和 [Vector](https://vector.dev/) 作为摄取源。不过,用户也可以借助任意 [ClickHouse Cloud 支持的集成](/zh/integrations/home),按自己的 schema 将数据直接发送到 ClickHouse。
选择“开始摄取”后,系统会提示你选择摄取源。托管 ClickStack 主要支持 OpenTelemetry 和 [Vector](https://vector.dev/) 作为摄取源。不过,用户也可以借助任意 [ClickHouse Cloud 支持的集成](/zh/integrations/home),按自己的 schema 将数据直接发送到 ClickHouse。
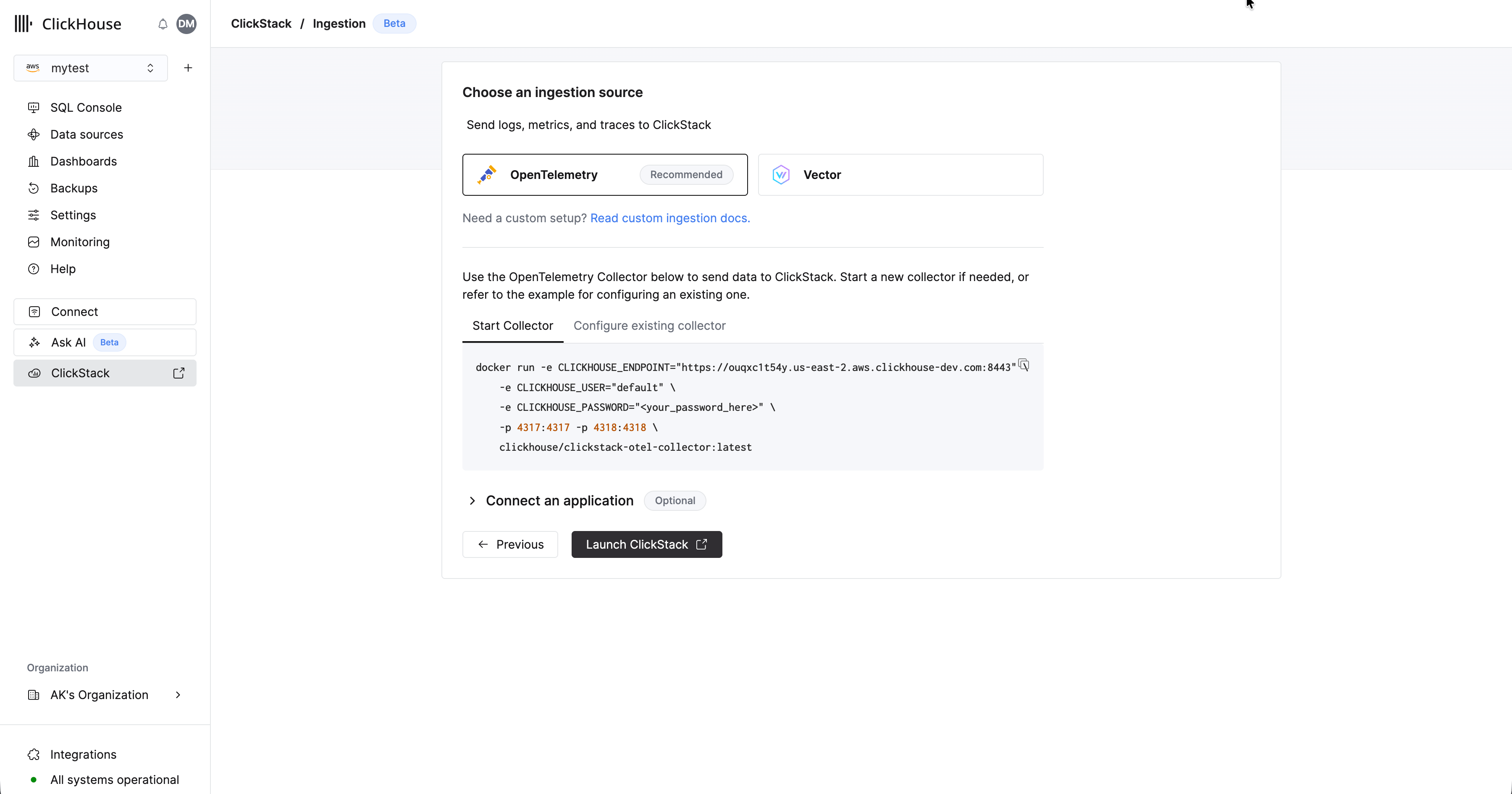 **推荐使用 OpenTelemetry**
强烈建议使用 OpenTelemetry 作为摄取格式。
它提供最简单、最优化的使用体验,并内置了专为与 ClickStack 高效配合而设计的开箱即用 schema。
要将 OpenTelemetry 数据发送到托管 ClickStack,建议使用 OpenTelemetry Collector。该 collector 充当网关,接收来自应用程序 (以及其他 collector) 的 OpenTelemetry 数据,并将其转发到 ClickHouse Cloud。
如果你还没有运行中的 collector,请按照以下步骤启动一个。如果你已有现成的 collector,也提供了一个配置示例。
### 启动一个 collector
以下内容假定你采用推荐方式,即使用 **ClickStack 发行版的 OpenTelemetry Collector**。它包含额外的处理能力,并专门针对 ClickHouse Cloud 进行了优化。如果你想使用自己的 OpenTelemetry Collector,请参阅[“配置现有 collector。”](#configure-existing-collectors)
要快速开始,请复制并运行下方显示的 Docker 命令。
**推荐使用 OpenTelemetry**
强烈建议使用 OpenTelemetry 作为摄取格式。
它提供最简单、最优化的使用体验,并内置了专为与 ClickStack 高效配合而设计的开箱即用 schema。
要将 OpenTelemetry 数据发送到托管 ClickStack,建议使用 OpenTelemetry Collector。该 collector 充当网关,接收来自应用程序 (以及其他 collector) 的 OpenTelemetry 数据,并将其转发到 ClickHouse Cloud。
如果你还没有运行中的 collector,请按照以下步骤启动一个。如果你已有现成的 collector,也提供了一个配置示例。
### 启动一个 collector
以下内容假定你采用推荐方式,即使用 **ClickStack 发行版的 OpenTelemetry Collector**。它包含额外的处理能力,并专门针对 ClickHouse Cloud 进行了优化。如果你想使用自己的 OpenTelemetry Collector,请参阅[“配置现有 collector。”](#configure-existing-collectors)
要快速开始,请复制并运行下方显示的 Docker 命令。
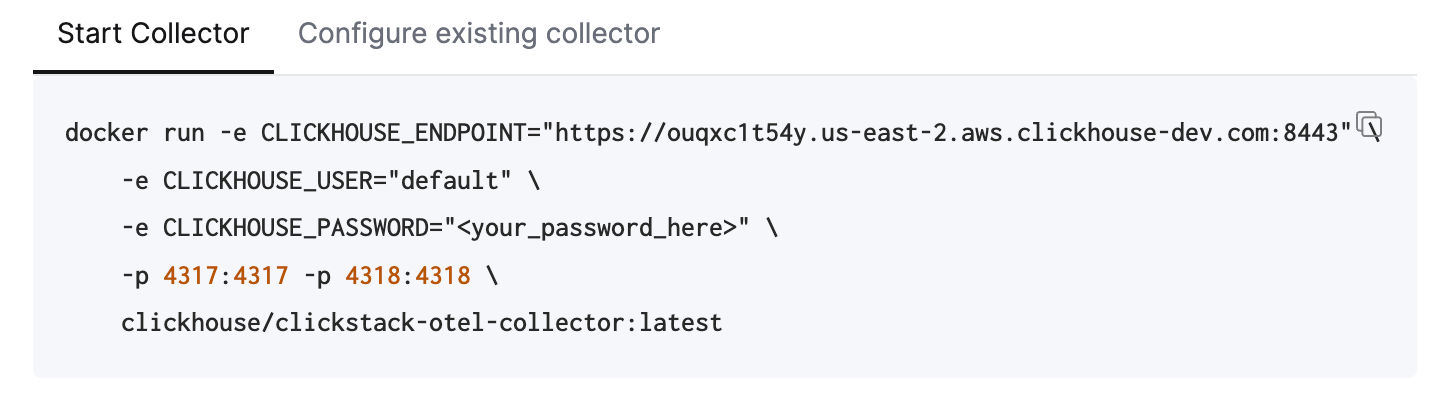 此命令应已预先填入你的连接凭据。
**部署到生产环境**
虽然此命令使用 `default` 用户连接到托管 ClickStack,但在[进入生产环境](/zh/clickstack/managing/overview#create-a-database-ingestion-user-managed)并修改配置时,你应创建一个专用用户。
运行这一条命令即可启动 ClickStack collector,并在 4317 (gRPC) 和 4318 (HTTP) 端口上开放 OTLP 端点。如果你已经有 OpenTelemetry 插桩和 agent,就可以立即开始将遥测数据发送到这些端点。
### 配置现有 collector
你也可以配置自己现有的 OpenTelemetry Collectors,或使用你自己的 collector 发行版。
**需要 ClickHouse exporter**
如果你使用自己的发行版,例如 [contrib image](https://github.com/open-telemetry/opentelemetry-collector-contrib),请确保其中包含 [ClickHouse exporter](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/clickhouseexporter)。
为此,我们提供了一个 OpenTelemetry Collector 配置示例。该示例使用经过适当设置的 ClickHouse exporter,并开放 OTLP receiver。此配置与 ClickStack 发行版所期望的接口和行为一致。
有关配置 OpenTelemetry collector 的更多详细信息,请参阅[“使用 OpenTelemetry 进行摄取。”](/zh/clickstack/ingesting-data/opentelemetry)
### 开始摄取 (可选)
如果你已有需要通过 OpenTelemetry 进行插桩的应用程序或基础设施,请前往 UI 中链接的相关指南。
要为应用程序添加插桩以收集链路追踪和日志,请使用[受支持的语言 SDKs](/zh/clickstack/ingesting-data/sdks)。它们会将数据发送到充当网关的 OpenTelemetry Collector,以摄取到托管 ClickStack 中。
日志可以通过以 agent 模式运行的 [OpenTelemetry Collectors 进行收集](/zh/clickstack/integration-examples/host-logs),并将数据转发到同一个 collector。对于 Kubernetes 监控,请遵循[专门指南](/zh/clickstack/integration-examples/kubernetes)。对于其他集成,请参阅我们的[快速入门指南](/zh/clickstack/integration-examples)。
### 演示数据
或者,如果你没有现成数据,可以试试我们的样本数据集之一。
* [示例数据集](/zh/clickstack/example-datasets/sample-data) - 从我们的公开演示中加载一个示例数据集,诊断一个简单问题。
* [本地文件和指标](/zh/clickstack/example-datasets/local-data) - 使用本地 OTel collector 加载本地文件,并在 OSX 或 Linux 上监控系统。
此命令应已预先填入你的连接凭据。
**部署到生产环境**
虽然此命令使用 `default` 用户连接到托管 ClickStack,但在[进入生产环境](/zh/clickstack/managing/overview#create-a-database-ingestion-user-managed)并修改配置时,你应创建一个专用用户。
运行这一条命令即可启动 ClickStack collector,并在 4317 (gRPC) 和 4318 (HTTP) 端口上开放 OTLP 端点。如果你已经有 OpenTelemetry 插桩和 agent,就可以立即开始将遥测数据发送到这些端点。
### 配置现有 collector
你也可以配置自己现有的 OpenTelemetry Collectors,或使用你自己的 collector 发行版。
**需要 ClickHouse exporter**
如果你使用自己的发行版,例如 [contrib image](https://github.com/open-telemetry/opentelemetry-collector-contrib),请确保其中包含 [ClickHouse exporter](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/clickhouseexporter)。
为此,我们提供了一个 OpenTelemetry Collector 配置示例。该示例使用经过适当设置的 ClickHouse exporter,并开放 OTLP receiver。此配置与 ClickStack 发行版所期望的接口和行为一致。
有关配置 OpenTelemetry collector 的更多详细信息,请参阅[“使用 OpenTelemetry 进行摄取。”](/zh/clickstack/ingesting-data/opentelemetry)
### 开始摄取 (可选)
如果你已有需要通过 OpenTelemetry 进行插桩的应用程序或基础设施,请前往 UI 中链接的相关指南。
要为应用程序添加插桩以收集链路追踪和日志,请使用[受支持的语言 SDKs](/zh/clickstack/ingesting-data/sdks)。它们会将数据发送到充当网关的 OpenTelemetry Collector,以摄取到托管 ClickStack 中。
日志可以通过以 agent 模式运行的 [OpenTelemetry Collectors 进行收集](/zh/clickstack/integration-examples/host-logs),并将数据转发到同一个 collector。对于 Kubernetes 监控,请遵循[专门指南](/zh/clickstack/integration-examples/kubernetes)。对于其他集成,请参阅我们的[快速入门指南](/zh/clickstack/integration-examples)。
### 演示数据
或者,如果你没有现成数据,可以试试我们的样本数据集之一。
* [示例数据集](/zh/clickstack/example-datasets/sample-data) - 从我们的公开演示中加载一个示例数据集,诊断一个简单问题。
* [本地文件和指标](/zh/clickstack/example-datasets/local-data) - 使用本地 OTel collector 加载本地文件,并在 OSX 或 Linux 上监控系统。
[Vector](https://vector.dev) 是一个高性能、厂商中立的可观测性数据管道,凭借灵活性高、资源占用低的特点,尤其常用于日志摄取。
将 Vector 与 ClickStack 搭配使用时,用户需要自行定义 schema。这些 schema 可以遵循 OpenTelemetry 约定,也可以完全自定义,用来表示用户定义的事件结构。
**必须提供时间戳**
对于托管 ClickStack,唯一的硬性要求是数据中包含一个**时间戳列** (或等效的时间字段) ,这可以在 ClickStack UI 中配置数据源时声明。
以下内容假设你已经有一个正在运行的 Vector 实例,并且已预先配置好摄取管道来传送数据。
### 创建数据库和表
Vector 要求在摄取数据之前先定义好表和 schema。
首先创建一个数据库。这可以通过 [ClickHouse Cloud 控制台](/zh/products/cloud/features/sql-console-features/sql-console) 完成。
例如,为日志创建一个数据库:
```sql theme={null}
CREATE DATABASE IF NOT EXISTS logs
```
然后创建一个表,使其 schema 与你的日志数据结构相匹配。下面的示例假设采用经典的 Nginx 访问日志格式:
```sql theme={null}
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
```
你的表必须与 Vector 生成的输出 schema 保持一致。请根据你的数据按需调整 schema,并遵循推荐的 [schema 最佳实践](/zh/concepts/best-practices/select-data-type)。
我们强烈建议你了解 [Primary keys](/zh/concepts/core-concepts/primary-indexes) 在 ClickHouse 中的工作原理,并根据你的访问模式选择排序键。有关如何选择主键,请参阅 [ClickStack-specific](/zh/clickstack/managing/performance-tuning#choosing-a-primary-key) 指南。
表创建完成后,复制所示的配置代码片段。按需调整输入以接入你现有的管道,并在需要时修改目标表和数据库。credentials 应已预先填充。
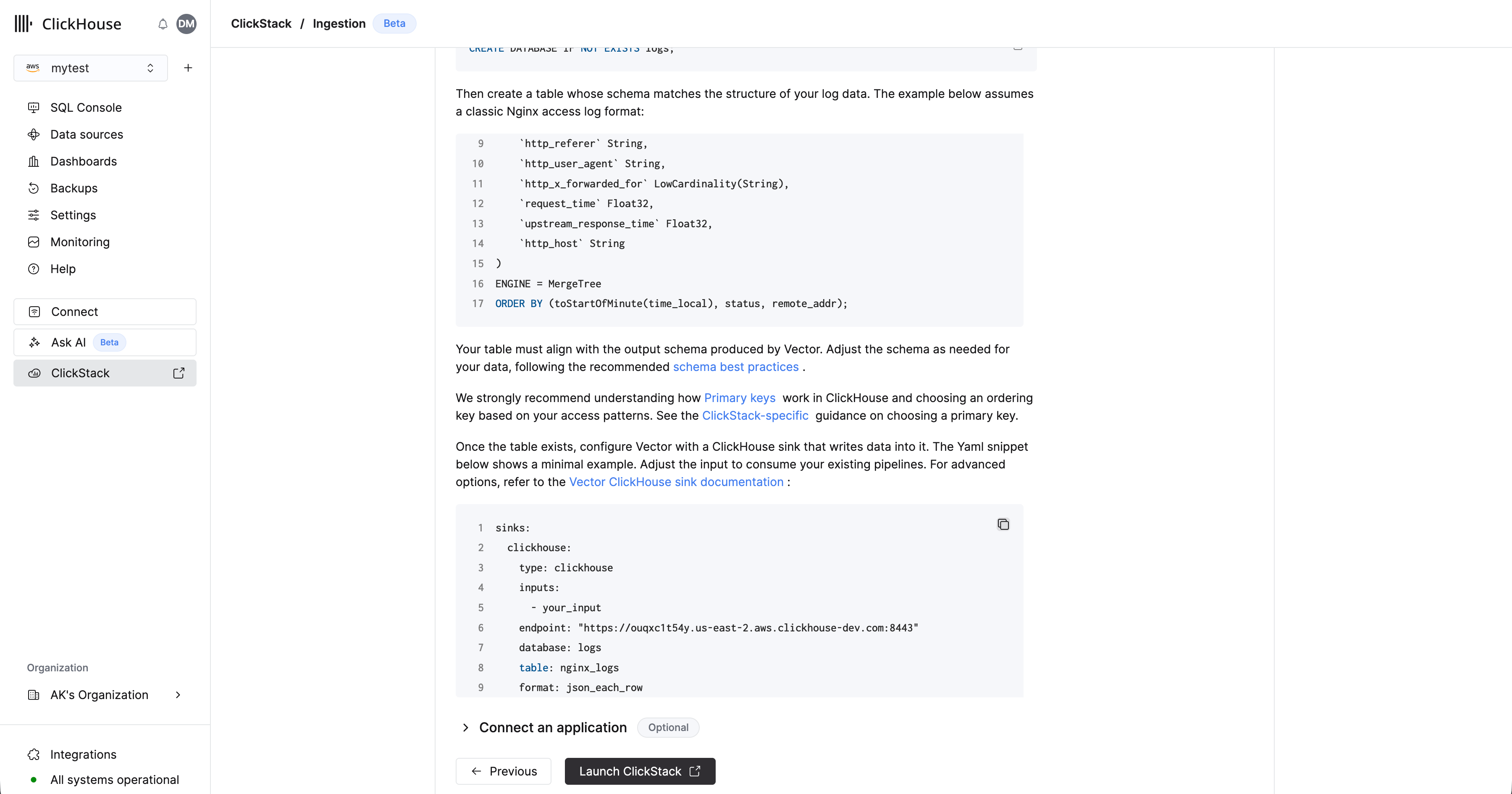 有关使用 Vector 摄取数据的更多示例,请参阅 ["使用 Vector 摄取数据"](/zh/clickstack/ingesting-data/vector),或查看 [Vector ClickHouse sink documentation](https://vector.dev/docs/reference/configuration/sinks/clickhouse/) 了解高级选项。
有关使用 Vector 摄取数据的更多示例,请参阅 ["使用 Vector 摄取数据"](/zh/clickstack/ingesting-data/vector),或查看 [Vector ClickHouse sink documentation](https://vector.dev/docs/reference/configuration/sinks/clickhouse/) 了解高级选项。
### 前往 ClickStack UI
选择“Launch ClickStack”以访问 ClickStack UI (HyperDX) 。系统会自动完成身份验证并将你重定向到相应页面。
系统会为所有 OpenTelemetry 数据预先创建数据源。
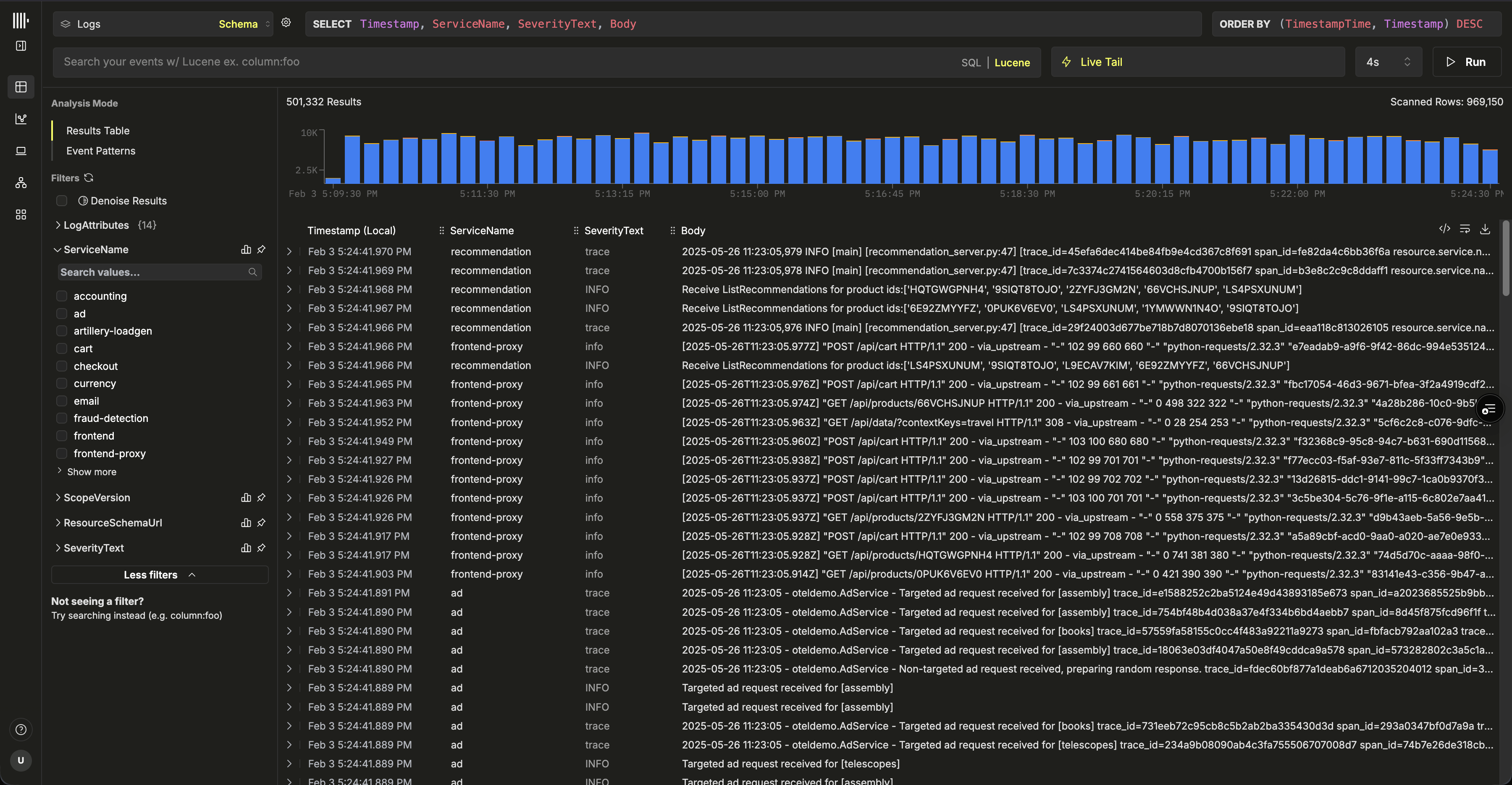 如果你使用的是 Vector,则需要自行创建数据源。首次登录时,系统会提示你创建一个。下面展示的是一个日志数据源的示例配置。
如果你使用的是 Vector,则需要自行创建数据源。首次登录时,系统会提示你创建一个。下面展示的是一个日志数据源的示例配置。
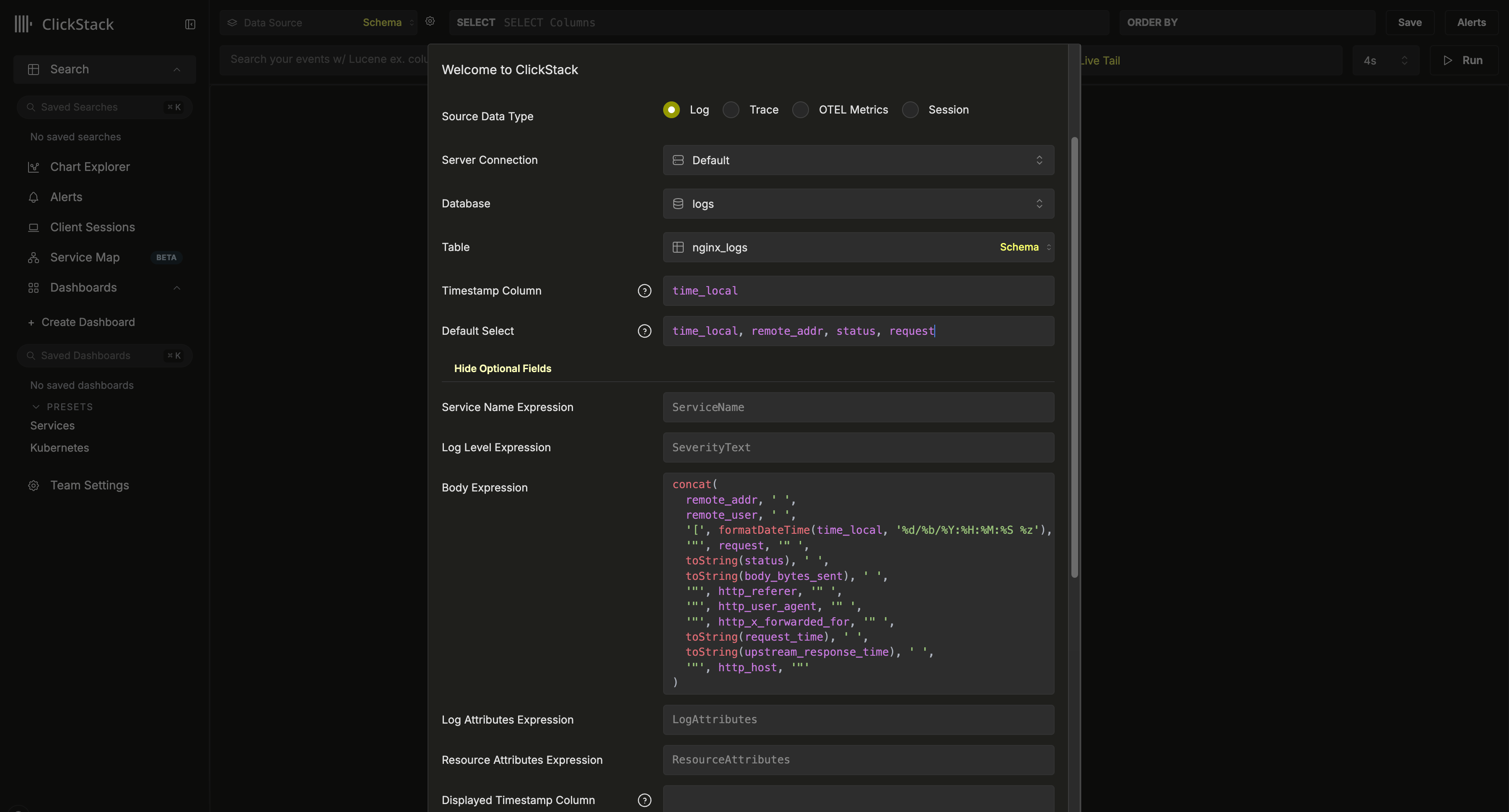 此配置假定使用 Nginx 风格的 schema,并将 `time_local` 列用作时间戳。在可能的情况下,它应为主键中声明的时间戳列。**此列为必填项**。
我们还建议更新 `Default SELECT`,以显式指定日志视图中返回哪些列。如果还有其他可用字段,例如服务名称、日志级别或 body 列,也可以一并配置。如果用于显示的时间戳列与表主键中使用且在上方配置的列不同,也可以对其进行覆盖。
在上面的示例中,数据里并不存在 `Body` 列。相反,它是通过一个 SQL 表达式定义的,用于根据现有字段重建一行 Nginx 日志。
有关其他可选配置,请参阅[配置参考](/zh/clickstack/managing/config)。
创建完成后,你将进入搜索视图,并可立即开始探索你的数据。
此配置假定使用 Nginx 风格的 schema,并将 `time_local` 列用作时间戳。在可能的情况下,它应为主键中声明的时间戳列。**此列为必填项**。
我们还建议更新 `Default SELECT`,以显式指定日志视图中返回哪些列。如果还有其他可用字段,例如服务名称、日志级别或 body 列,也可以一并配置。如果用于显示的时间戳列与表主键中使用且在上方配置的列不同,也可以对其进行覆盖。
在上面的示例中,数据里并不存在 `Body` 列。相反,它是通过一个 SQL 表达式定义的,用于根据现有字段重建一行 Nginx 日志。
有关其他可选配置,请参阅[配置参考](/zh/clickstack/managing/config)。
创建完成后,你将进入搜索视图,并可立即开始探索你的数据。
就是这样——你已全部设置就绪。🎉
现在就开始探索 ClickStack:搜索日志和链路追踪,查看日志、链路追踪和指标如何实时关联,构建仪表盘,探索服务地图,发掘 Event deltas 和 Patterns,并设置告警以提前发现问题。
### 选择服务
在 ClickHouse Cloud 首页中,选择要为其启用托管 ClickStack 的服务。
**资源估算**
本指南假设您已预配足够的资源,以处理计划使用 ClickStack 摄取和查询的可观测性数据量。要估算所需资源,请参阅[资源估算](/zh/clickstack/managing/estimating-resources)指南。
如果您的 ClickHouse 服务已经承载现有工作负载,例如实时应用分析,我们建议使用 [ClickHouse Cloud 的仓库功能](/zh/products/cloud/features/infrastructure/warehouses) 创建一个子服务,以隔离可观测性工作负载。这样既能确保现有应用不受影响,又能让两个服务都能访问这些数据集。
### 前往 ClickStack UI
在左侧导航菜单中选择 'ClickStack'。系统会将你重定向到 ClickStack UI,并根据你的 ClickHouse Cloud 权限自动完成身份验证。
如果你的服务中已存在任何 OpenTelemetry 表,系统会自动检测到它们,并创建相应的数据源。
**自动检测数据源**
自动检测依赖于 ClickStack 版 OpenTelemetry collector 提供的标准 OpenTelemetry 表 schema。系统会为拥有最完整表集合的数据库创建相应的源。如有需要,还可以将其他表添加为[单独的数据源](/zh/clickstack/managing/config#datasource-settings)。
如果自动检测成功,你将进入搜索视图,并可立即开始探索你的数据。
如果这一步成功,那就大功告成了——你已经全部就绪 🎉;否则请继续设置摄取。
### 设置摄取
如果自动检测失败,或您没有现有的表,系统将提示您配置摄取。
选择 "Start Ingestion",系统将提示您选择摄取来源。托管 ClickStack 支持 OpenTelemetry 和 [Vector](https://vector.dev/) 作为主要摄取来源。此外,用户也可以通过任意 [ClickHouse Cloud 支持的集成](/zh/integrations/home),使用自定义 schema 将数据直接发送至 ClickHouse。
**强烈推荐使用 OpenTelemetry**
强烈建议使用 OpenTelemetry 作为摄取格式。
它提供了最简单、最优化的体验,并且内置了专为与 ClickStack 高效配合而设计的 schema。
要将 OpenTelemetry 数据发送到托管 ClickStack,建议使用 OpenTelemetry Collector。该 collector 充当 gateway,接收来自应用程序 (以及其他 collector) 的 OpenTelemetry 数据,并将其转发到 ClickHouse Cloud。
如果你还没有正在运行的 collector,请按以下步骤启动一个。如果你已有现成的 collector,也提供了一个 configuration 示例。
### 启动 collector
以下内容假定你采用推荐方式:使用 **ClickStack 发行版的 OpenTelemetry Collector**。它包含额外的处理能力,并专门针对 ClickHouse Cloud 进行了优化。如果你想使用自己的 OpenTelemetry Collector,请参阅[“配置现有 collector。”](#configure-existing-collectors)
为了快速开始,请复制并运行下方所示的 Docker 命令。
**请将此命令中的服务 credentials 替换为你在创建服务时记录的信息。**
**部署到 production**
虽然此命令使用 `default` 用户连接托管 ClickStack,但在[进入 production](/zh/clickstack/managing/production#create-a-database-ingestion-user-managed)并修改配置时,你应创建一个专用用户。
运行这一条命令即可启动 ClickStack collector,并在 4317 (gRPC) 和 4318 (HTTP) 端口上暴露 OTLP 端点。如果你已经有 OpenTelemetry instrumentation 和 agent,便可立即开始将 telemetry data 发送到这些端点。
### 配置现有 collector
你也可以配置自己现有的 OpenTelemetry Collectors,或使用你自己的 collector 发行版。
**需要 ClickHouse exporter**
如果你使用自己的发行版,例如 [contrib image](https://github.com/open-telemetry/opentelemetry-collector-contrib),请确保其中包含 [ClickHouse exporter](https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/clickhouseexporter)。
为此,系统提供了一个 OpenTelemetry Collector configuration 示例,它使用了经过适当设置的 ClickHouse exporter,并暴露 OTLP receivers。该 configuration 与 ClickStack 发行版所期望的 interfaces 和行为保持一致。
下面展示了此配置的一个示例 (如果从 UI 复制,环境变量会预先填入) :
```yaml theme={null}
receivers:
otlp/hyperdx:
protocols:
grpc:
include_metadata: true
endpoint: "0.0.0.0:4317"
http:
cors:
allowed_origins: ["*"]
allowed_headers: ["*"]
include_metadata: true
endpoint: "0.0.0.0:4318"
processors:
batch:
memory_limiter:
# 最大内存的 80%,上限为 2G,低内存环境请适当调整
limit_mib: 1500
# 上限的 25%,上限为 2G,低内存环境请适当调整
spike_limit_mib: 512
check_interval: 5s
connectors:
routing/logs:
default_pipelines: [logs/out-default]
error_mode: ignore
table:
- context: log
statement: route() where IsMatch(attributes["rr-web.event"], ".*")
pipelines: [logs/out-rrweb]
exporters:
debug:
verbosity: detailed
sampling_initial: 5
sampling_thereafter: 200
clickhouse/rrweb:
database: default
endpoint:
password:
username: default
ttl: 720h
logs_table_name: hyperdx_sessions
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
clickhouse:
database: default
endpoint:
password:
username: default
ttl: 720h
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
traces:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
metrics:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/in:
receivers: [otlp/hyperdx]
exporters: [routing/logs]
logs/out-default:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/out-rrweb:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse/rrweb]
```
有关配置 OpenTelemetry collector 的更多详细信息,请参阅[“使用 OpenTelemetry 进行摄取。”](/zh/clickstack/ingesting-data/opentelemetry)
### 开始摄取 (可选)
如果你已有要使用 OpenTelemetry 进行 instrument 的应用程序或基础设施,请前往“连接应用程序”中的相关指南。
要为应用程序添加 instrument 以收集链路追踪和日志,请使用[受支持的语言 SDK](/zh/clickstack/ingesting-data/sdks)。它们会将数据发送到充当 gateway 的 OpenTelemetry Collector,以便摄取到托管 ClickStack。
日志可以通过以 agent 模式运行的 [OpenTelemetry Collectors 进行收集](/zh/clickstack/integration-examples/host-logs),并将数据转发到同一个 collector。对于 Kubernetes Monitoring,请遵循[专门指南](/zh/clickstack/integration-examples/kubernetes)。对于其他 integrations,请参阅我们的[快速入门指南](/zh/clickstack/integration-examples)。
[Vector](https://vector.dev) 是一个高性能、供应商中立的可观测性数据管道,凭借其灵活性和较低的资源占用,尤其适合用于日志摄取。
将 Vector 与 ClickStack 搭配使用时,用户需要自行定义 schema。这些 schema 可以遵循 OpenTelemetry 约定,也可以完全自定义,用来表示用户定义的事件结构。
**必须包含时间戳**
对于托管 ClickStack,唯一的硬性要求是数据中必须包含一个**时间戳列** (或等效的时间字段) ,该列可在 ClickStack UI 中配置数据源时声明。
以下内容假设你已经运行了一个 Vector 实例,并且已预先配置好摄取管道来传送数据。
### 创建数据库和表
Vector 要求在开始数据摄取之前,先定义好表和 schema。
首先创建一个数据库。可通过 [ClickHouse Cloud 控制台](/zh/products/cloud/features/sql-console-features/sql-console) 完成此操作。
例如,为日志创建一个数据库:
```sql theme={null}
CREATE DATABASE IF NOT EXISTS logs
```
然后创建一个表,使其 schema 与日志数据的结构一致。下面的示例假设使用经典的 Nginx 访问日志格式:
```sql theme={null}
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
```
你的表必须与 Vector 生成的输出 schema 保持一致。请根据你的数据按需调整 schema,并遵循推荐的 [schema 最佳实践](/zh/concepts/best-practices/select-data-type)。
我们强烈建议你先了解 [Primary keys](/zh/concepts/core-concepts/primary-indexes) 在 ClickHouse 中的工作机制,并根据你的访问模式选择排序键。有关如何选择主键,请参阅 [ClickStack 专用](/zh/clickstack/managing/performance-tuning#choosing-a-primary-key) 指南。
创建好表后,复制所示的配置片段。按需调整输入,以使用你现有的管道,以及目标表和数据库。凭据应已预先填入。
有关使用 Vector 摄取数据的更多示例,请参阅 ["使用 Vector 进行摄取"](/zh/clickstack/ingesting-data/vector),或查看 [Vector ClickHouse sink 文档](https://vector.dev/docs/reference/configuration/sinks/clickhouse/),了解高级选项。
### 前往 ClickStack UI
完成摄取设置并开始发送数据后,选择 "Next"。
如果你已按照本指南摄取 OpenTelemetry 数据,系统会自动创建数据源,无需进一步设置。你可以立即开始使用 ClickStack。系统会将你引导至搜索视图,并自动选中一个数据源,以便你立即开始查询。
就这样——一切已准备就绪 🎉。
如果你是通过 Vector 或其他来源摄取数据,系统会提示你配置数据源。
上述配置假定使用的是 Nginx 风格的 schema,并将 `time_local` 列用作时间戳。在可能的情况下,这应当是主键中声明的时间戳列。**此列为必填项**。
我们还建议更新 `Default SELECT`,以显式定义日志视图中返回哪些列。如果还有其他可用字段,例如服务名称、日志级别或 body 列,也可以一并配置。如果时间戳显示列与表主键中使用并在上方配置的列不同,也可以对其进行覆盖。
在上面的示例中,数据中不存在 `Body` 列。相反,它是通过一个 SQL expression 定义的,用于根据现有字段重建一条 Nginx 日志行。
如需了解其他可用选项,请参阅[配置参考](/zh/clickstack/managing/config#hyperdx)。
配置好数据源后,点击 "Save" 并开始探索你的数据。
## 其他任务
### 授予对托管 ClickStack 的访问权限
1. 在 ClickHouse Cloud 控制台中打开您的服务
2. 前往 **设置** → **SQL 控制台访问**
3. 为每位用户设置合适的权限级别:
* **服务管理员 → 完全访问** - 启用告警所必需
* **服务只读 → 只读** - 可查看可观测性数据并创建仪表盘
* **无访问权限** - 无法访问 HyperDX
**告警需要管理员权限**
要启用告警,至少需要有一位具备 **服务管理员** 权限的用户 (在 **SQL 控制台访问** 下拉菜单中对应为 **完全访问**) 至少登录一次 HyperDX。这样会在数据库中预配一个专门用于运行告警查询的用户。
### 搭配只读计算资源使用 ClickStack
ClickStack UI 可以完全在只读的 ClickHouse Cloud 服务上运行。如果你希望将摄取工作负载与查询工作负载隔离开来,推荐采用这种设置。
#### ClickStack 如何选择 计算资源
ClickStack UI 始终连接到它在 ClickHouse Cloud 控制台中启动时所在的 ClickHouse 服务。
这意味着:
* 如果你从只读服务打开 ClickStack,ClickStack UI 发出的所有查询都会在该只读 计算资源 上运行。
* 如果你从读写服务打开 ClickStack,ClickStack 则会改用该 计算资源。
无需在 ClickStack 内进行任何额外配置来强制启用只读行为。
#### 推荐配置
要在只读计算资源上运行 ClickStack:
1. 在仓库中创建或找到一个配置为只读的 ClickHouse Cloud 服务。
2. 在 ClickHouse Cloud 控制台中,选择该只读服务。
3. 在左侧导航菜单中启动 ClickStack。
启动后,ClickStack UI 会自动绑定到该只读服务。
### 添加更多数据源
ClickStack 原生支持 OpenTelemetry,但并不局限于 OpenTelemetry——如果需要,也可以使用你自己的表 schema。
下面说明如何添加自动配置之外的其他数据源。
#### 使用 OpenTelemetry schema
如果你使用 OTel collector 在 ClickHouse 中创建数据库和表,请在创建数据源表单中保留所有默认值,并在 `Table` 字段中填写 `otel_logs`,以创建日志数据源。其余设置应会自动识别,然后即可点击 `Save New Source`。
要为链路追踪和 OTel 指标创建数据源,你可以从顶部菜单中选择 `创建新数据源`。
在这里,先选择所需的数据源类型,再选择对应的表。例如,对于链路追踪,请选择表 `otel_traces`。所有设置都应自动识别。
**关联来源**
请注意,ClickStack 中的不同数据源 (例如日志和链路追踪) 可以彼此关联。要启用此功能,需要在每个数据源上进行额外配置。例如,你可以在日志数据源中指定对应的链路追踪数据源;反之,也可以在链路追踪数据源中指定对应的日志数据源。更多详情,请参见 [“关联来源”](/zh/clickstack/managing/config#correlated-sources)。
#### 使用自定义 schema
如果要将 ClickStack 连接到已有数据的现有服务,可根据需要填写 database 和表设置。如果各表符合适用于 ClickHouse 的 OpenTelemetry schema,系统会自动检测这些设置。
如果使用自定义 schema,我们建议创建一个日志数据源,并确保指定了必需字段。更多详情请参阅["日志数据源设置"](/zh/clickstack/managing/config#logs)。
## schema 选择:Map 与 JSON
默认情况下,ClickStack 将属性存储为 `Map(LowCardinality(String), String)` 列。这是可观测性 workloads 推荐使用的 schema。结合 [bucketed map serialization](/zh/reference/data-types/map#bucketed-map-serialization) 以及针对 map 键和值的文本索引,它可以实现有针对性的 lookup,同时避免动态 JSON 子列逐键摄取带来的额外开销。
`JSON` 类型的 schema 也已提供,目前处于 Beta 阶段,适合在属性键集合较小且稳定的 workloads 上进行评估。**不建议**将其作为默认选项。有关完整对比以及启用 JSON 支持所需的环境变量,请参见 [Map vs JSON type](/zh/clickstack/ingesting-data/schema/map-vs-json)。